
Phishing Email Detection Using Classification
- Why: Data provided by Kaggle is important information for banking as it helps us to focus on predicting if a received email is a phishing email or not.
- Value: Banking organizations can improve security by strategically vetting large amounts of email data to ensure they are not exposed to attacks through phishing emails.
Data Source: Data obtain from Kaggle contains over 28,000 rows of email body text and it classifies them between phishing or safe email.
Analytical Process
- Obtained data from Kaggle would get stored in a SQL table via an API.
- Data then would be used to train through an algorithm to vet future incoming emails.
- Python will be used to achieve algorithms.
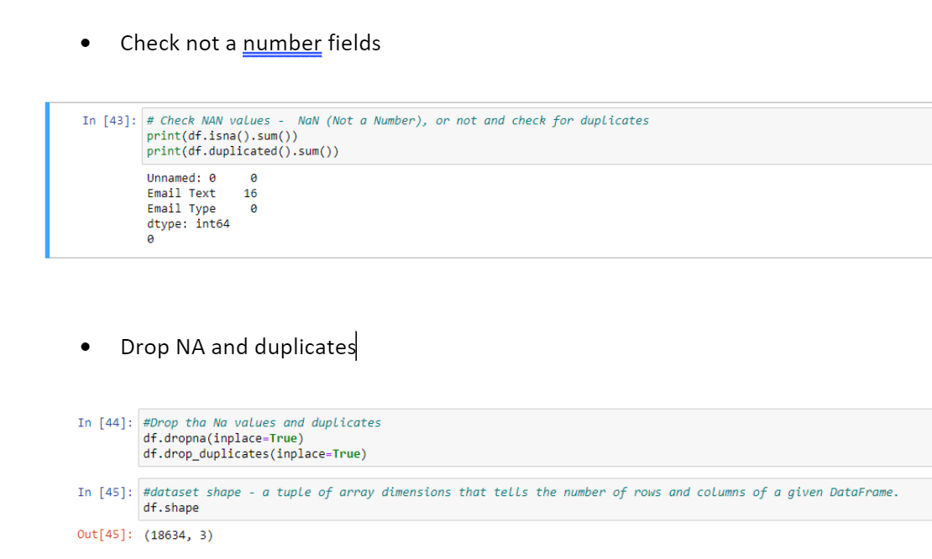
Product Attributes were collected through Python. Data was subject through a text analysis as main attribute is not tabular. This pre-process reduce training data to 18,634 instances.
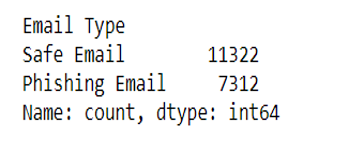
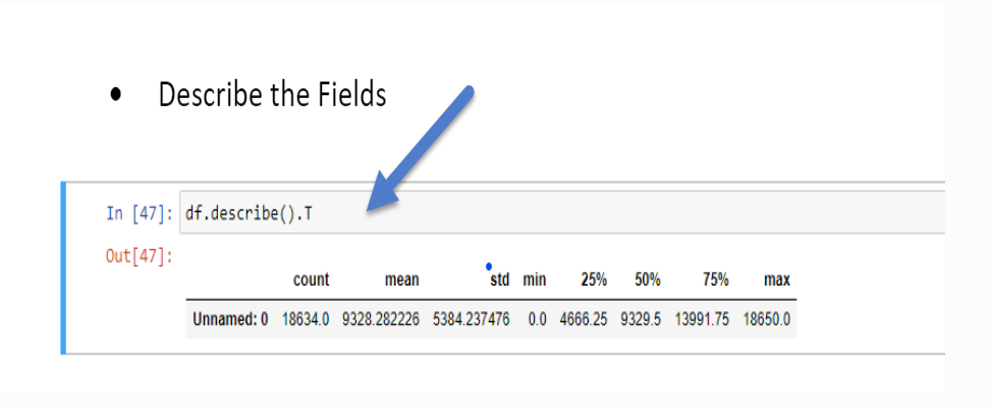
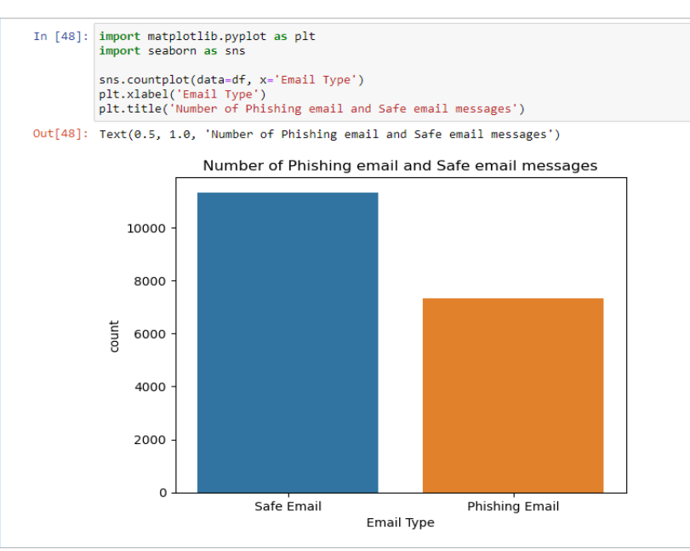
Product Attributes were collected using Python. This summary highlights that text dataset (emails) were classified into two types: Safe and Phishing emails. Also, shown below is a description of the fields.
K-Fold Random Forest: Popular algorithm for Classification. This algorithm is a tree-based ML that leverages the power of multiple decision trees where each node is a random subset of features to calculate the output (Sharma 2020).
Process
- Data was set through pre-processing steps:
- Removal of instances with missing values.
- Replacement of Training spaces and characters.
- Update of all characters to lower case and removal of duplicates records.
- Removal of extra columns and export to ascii format.
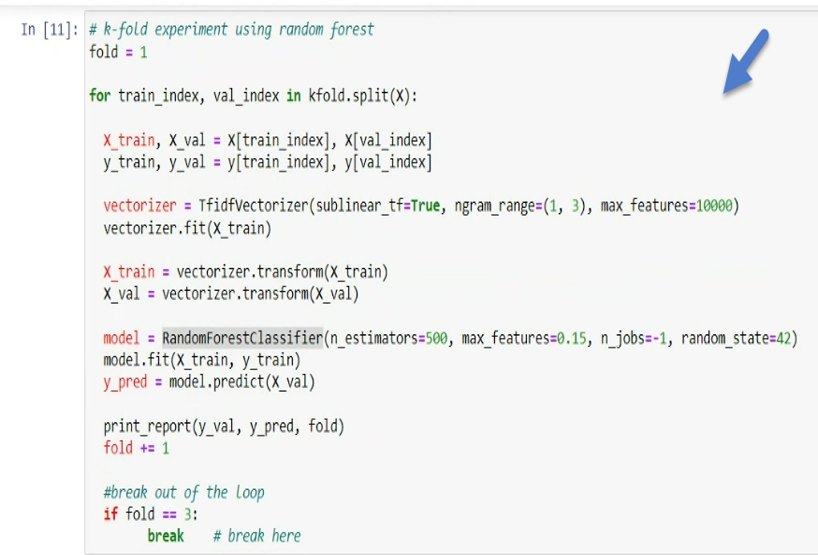
- Data was trained on 2/3 of the data with a tree forest of 500-fold.
- Data was set to .15 features to be considered when looking for best split.
- Job was set not to run in parallel.
- Randomness was set to 42
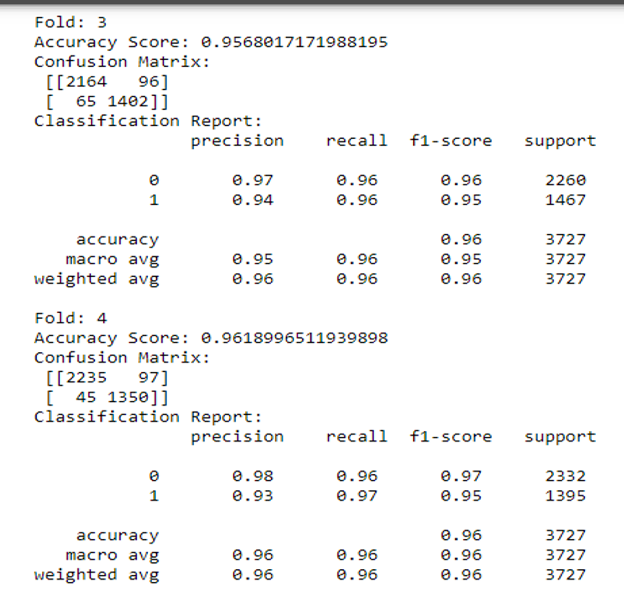
Confusion Matrix was applied to provide measures of model’s accuracy with k-fold random forest algorithm which demonstrated an accuracy of 95.5%

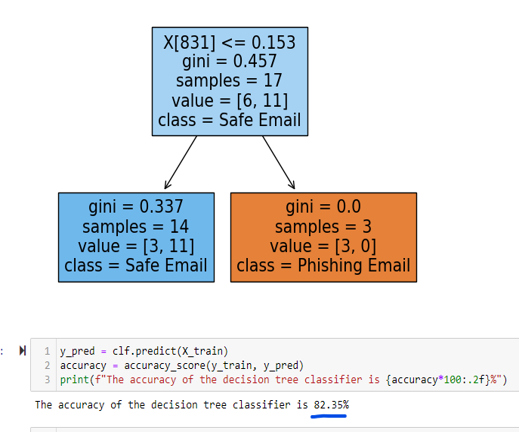
Decision Tree Classifier: which is a supervised machine learning algorithm used in our case for classification. This “decision tree is a simple series of sequential decisions made to reach a specific result” (Sharma 2000.)
Process
- As our data set is a semi-structured, text mining was applied to classify data.
- Data set was pre-processed by cleaning it and converting it to UTF8, tab delimited
- Using Python data was set for patter recognition by creating a column for each free text subsequently providing a class label.
Network Intrusion Detection Using Classification
- Why: This dataset is important to the banking industry to simulate whether a network is under attack and an intrusion to the network has occurred.
- Value: Financial institutions can benefit from this analysis to determine what is a benign attack and what classifies as a network intrusion to quickly respond.
Data Source: Data obtained from Kaggle contains over 170,000 rows of data going through a network during a morning working day.
Analytical Process
- Obtained data from Kaggle would get stored in a SQL table via an API.
- Data then would be used to train through an algorithm to vet future incoming emails.
- Python will be used for algorithms and visualizations
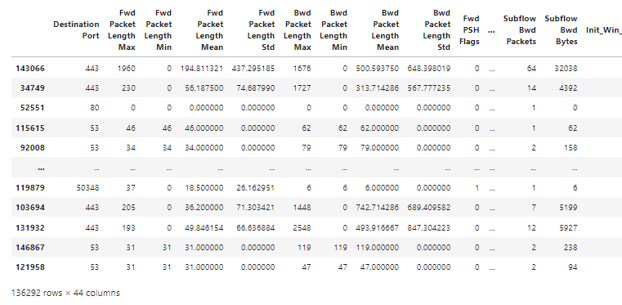
Product Attributes were imported in Python with data pre-processing and training of the models for the y_ train output.
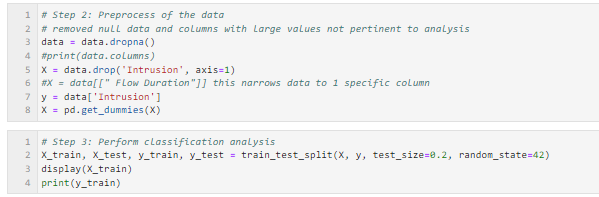
Random Forest: Machine learning classification method to predict the class or category of an input data (benign or intrusion)
Process
- Dataset uploaded to Python with preprocessing completed for analysis to remove null values and large values not pertinent for analysis
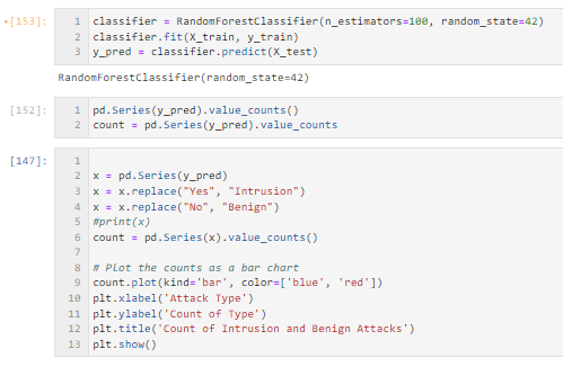
- RandomForestClassifier used to classify and train x and y
- Series created for value counts of benign and intrusion value counts
- Bar chart visualization created with x and y labels updated (reference Network Intrusion Visualization)
Analysis of Malicious URLs Data
URL Country Identification: URLs and IPs were run through an API to determine country location (http://api.ipstack.com). Due to limitations on volume of data accessible via API (without paying a significant fee), the data returned focuses on foreign domains only.
The results of this analysis were placed into a geospatial visualization, which places a larger dot on the countries which were identified as having more malicious URLs in the dataset. This visualization offers a quick yet valuable snapshot which highlights the countries with the most malicious URLs.
This data is useful for identifying countries and domains which may be high risk and warrant additional scrutiny or countermeasures.